
- Wed 11 April 2018
- regionalization

There is a classic response whenever anyone proposes a new standard in computing, and you would be forgiven for rolling your eyes a bit at the idea of a new format for LCIA data. As someone that has to support multiple formats, I know that each new standard is a burden for multiple programmers - or worse, will simply be ignored. Sometimes we need a new data format, though, and this blog post will (hopefully!) describe why we need a new format, and then explain the decisions made during that format's development.
You can see a complete example of the format in action here.
Why we need a new standard
There is a simple reason that we need a data format for regionalized LCIA methods: we just don't have one right now. The three big LCIA methods released in last few years are ReCiPe 2016, Impact World+, and LC-IMPACT. All three of these included at least some degree of regionalization, but only one (IMPACT World+) provides characterization factors in any standardized format at all, and that format - ecospold version 1 - is now deprecated. The other two methods, and the ecoinvent centre themselves, all provide characterization factors in custom spreadsheets. Spreadsheets can't conveniently include spatial data, and given the prevalence of custom spreadsheets, it might be fair to say that we don't have a standard format for LCIA data in general.
The two existing formats are ecospold version 1 and ILCD. Both are XML, and are highly structured, which means that you can't read or write them without writing significant code. They both have support for characterization factor uncertainty, but neither have any support for regionalization. However, the biggest argument against these formats is their lack of use by the community and LCIA developers.
It is important to differentiate between a format requirements for data interchange, and the requirements for data being used directly by LCA software. Data interchange is between computers and programming languages, so compatibility and simplicity are priorities; when using the data, the primary concern is performance, so formats like HDF, Parquet, and Geopackage are a better fit. It is easy and quick to transform from a good interchange format to a more specialized format.
Wishlist for a new option
Here is my personal wishlist for a new LCIA data format:
- Software independency, including the ability to be useful in non-LCA software. Must be trivial to read and write, both for computers and people.
- Clear linking to multiple elementary flow nomenclatures. People use both the ecoinvent (ecospold) and ELCD (ILCD) systems, and LCIA method are the best people to choose which elementary flows from each system meet their model assumptions. If you let the software people do it, you will get a different mapping from each LCA software, and probably a lot of mistakes.
- Support for uncertainty distributions, including incomplete distributions (i.e. just giving a standard deviation instead of a full PDF)
- Support for regionalization, including vector (points, lines, polygons) and raster (pixel) spatial scales; such support should include "no-data" values and coordinate reference systems.
- Explicit licensing
- Explicit versioning
- A data integrity check
Data Packages rescue us from the Tower of Babel
The challenges we face in LCA aren't unique - almost everyone is dealing with problems of data management and interchange. Because so many people are struggling with the same issues, there are also people working on these problems full-time, and producing simple, elegant solutions. The solution I have chosen for a new LCIA format is called data package, from the Open Knowledge Foundation. They do a good job describing what a data package is; you should just read their introduction. I first found out about data packages from the Open Power System Data (OPSD) project (which is itself a great resource for LCA people), and both heard good things and saw for myself how this format could meet all the listed objectives:
- Software independency: Characterization factor (CF) data is stored in CSV, and metadata in JSON, both of which are easily consumed by every computer language.
- Clear linking. The metadata specification can be adapted to allow ecoinvent and ELCD flows to be listed explicitly.
- Support for uncertainty distributions: No problem, especially when using standardized terms and definitions from the UncertWeb project.
- Support for regionalization: Provided by the draft Spatial Data Package.
- Explicit licensing: Built into the data package standard.
- Explicit versioning: Built into the data package standard.
- Data integrity: Built into the data package standard.
Choices during development
While existing standards where used as much as possible, some judgment calls had to be made during the format development. You can debate them in the comments :)
Fitting multi-dimensional data into a two-dimensional CSV
This is the most controversial decision, but I don't see any other realistic option. There is a clear preference among LCIA methods for releasing CF data in spreadsheets, and data package also recommends CSVs. The problem is that most released spreadsheets look like this:
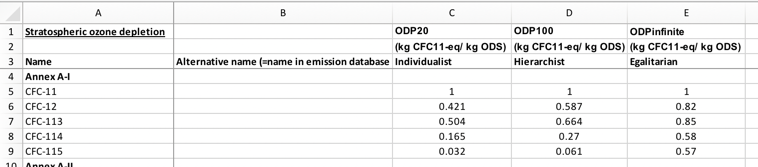
However, when we add uncertainty information (even simple uncertainty information - most distributions would require multiple columns), this abstraction breaks down. We have what Pandas calls a MultiIndex:
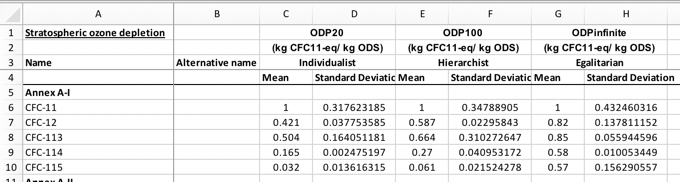
The problem is that each column is not self-contained, but some columns refer to other columns. This is not allowed by the tabular data package standard, and for good reason. In a data interchange format, there is no need to compress multiple tables into a single file when you can give each file separately. In this example, the problem is that multiple impact categories (or, more precisely, multiple combinations of impact category, weighting, and normalization) are provided in the same file. This might be convenient to calculate or get an overview of the CFs, but can be avoided in a data interchange format. In the proposed format, each combination of spatial scale, uncertainty distribution, impact category, weighting, and normalization is a separate CSV file. A CSV file conforming to this standard would look like this:
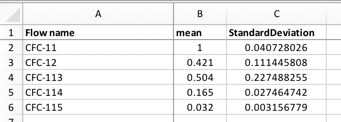
All the LCIA metadata is in the metadata file, in a standard fashion - no more writing custom parsers for each Excel workbook. The metadata also defines precisely what e.g. CFC-11 means, including the archetypes (category and subcategory). The metadata also defines exactly how to interpret each column heading.
For analysis afterwards, it is pretty easy to either load multiple CSVs or join them together into a single Workbook. The OPSD makes multiple versions of their data available (expand "Alternative file formats" on the linked webpage), some of which include multiindices; a centralized repository of LCIA data could also provide such conversion services on-demand.
Labeling of uncertainty fields
The labels for describing uncertainty are based on the UncertWeb project, which is finished and slowly disappearing from the web. However, the provided a decent set of statistical definitions in JSON, both for distributions and other quantities. We don't need to invent another format for describing uncertainty data with magic numbers and other silliness.
Differences between vector and raster formats
The Spatial Data Package recommends separating numerical data from geospatial definitions, and we follow this recommendation. However, this mental model breaks down when we work with rasters - you can't separate the numerical data from the raster file in any practical fashion. This means we have CSVs for vector spatial scales, but not for rasters. We also have a separate schema to define raster bands.
Next steps
The broader long-term goal is to make regionalization boring and commonplace, and facilitating LCIA data interchange is an important step towards that goal.
The UNEP-SETAC working group on LCIA regionalization will review the standard, and my colleagues and I will test the format by implementing the ReCiPe 2016 method. I will also add support for this format in Brightway2. There will certainly be small changes needed, but I think there is a solid foundation here - and hopefully we won't have any more conference talks entitled LCIA implementation in software: Alarming differences.
I will also develop a simple web interface to generate and validate LCIA methods in this data format, building off of the data package creator.