
- Sun 05 November 2023
- ecoinvent

Note: This is part one of a series on working with ecoinvent. Next week will be matrix construction and LCA calculations. All code given here is also available as a Jupyter notebook.
Working the the ecoinvent ecospold2 files isn't easy. This is a step by step guide to using this data. You must have an ecoinvent license to do the steps listed here.
Setting up the data processing environment
First, let's create a new virtual environment. The exact command will depend on your operating system, and you will need to install Python. My virtual environments are stored in the directory virtualenvs, but this can be changed to suit your guidelines or preferences.
python -m venv virtualenvs/ecoinvent
Next, we need to activate that environment. This command also varies by operating system. We can also install some helper libraries, and especially ecoinvent_interface:
source virtualenvs/ecoinvent/bin/activate
pip install pyecospold ecoinvent_interface pandas openpyxl tqdm
You might also want to install ipython or jupyter, or set up your code editor or IDE to point to this virtual environment.
Downloading some data
In whatever Python interpreter you prefer, you can now download an ecoinvent release. Let's use APOS and 3.7.1 (picked at random):
import ecoinvent_interface as ei
settings = ei.Settings(username="XXX", password="XXX")
release = ei.EcoinventRelease(settings)
release.list_versions()
release.list_system_models('3.7.1')
RELEASE_PATH = release.get_release(
version='3.7.1',
system_model='apos',
release_type=ei.ReleaseType.ecospold
)
The are different packages for each release. We are downloading ReleaseType.ecospold, which is the set of unit process datasets - we want to do our own LCI and LCIA calculations.
Speaking of LCIA, we also need the file with impact categories and characterization methods:
release.list_extra_files('3.7.1')
LCIA_PATH = release.get_extra(version='3.7.1', filename='ecoinvent 3.7.1_LCIA_implementation.7z')
LCA as a graph
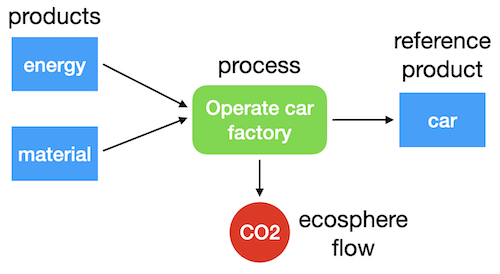
The fundamental model in life cycle assessment is a graph with nodes and edges. We have three types of nodes: processes, products (both goods and services), and ecosphere flows [1].
Processes produce and consume products. Processes don't exist in the database by accident - each one was consciously chosen, and that choice is normally because of the production or consumption of a specific product. We call this specific product the reference product of the process. Reference products are normally produced, but can also be consumed. For example, a waste treatment process could consume waste as its reference product.
Some processes might be multifunctional - i.e. they have more than one functional product. Multifunctionality can be handled in different ways, and is outside the scope of this document. We are working with ecoinvent releases, where process is associated with one reference product, regardless of how many functional products were given in the original dataset before the system model was applied. It's important that we have the same number of processes as products in order to construct a square and non-singular technosphere matrix.
Edges connect nodes. Nodes have a lot of metadata about the processes, products, and ecosphere flows they represent, but our directed edges only need the source and target nodes and the amount [2]. Brightway also gives edges a type, but the type can be inferred from the source and target nodes:
- consumption: A product node as source, a process node as target
- production: A process node as source, a product as target
- ecosphere: A process node and an ecosphere flow node, in either direction
Here is an example of a simple supply chain graph:
How does ecoinvent provide information about nodes? It stores some information in the MasterData subdirectory. The three node types are in three different files.
Processes: ActivityIndex.xml
Here is an example element from ActivityIndex.xml:
<activityIndexEntry
id="f7e93a25-56e4-4268-a603-3bfd57c79eff"
activityNameId="c2d58788-238b-464b-89c5-6b075d323033"
geographyId="34dbbff8-88ce-11de-ad60-0019e336be3a"
startDate="1981-01-01" endDate="2005-12-31"
specialActivityType="0"
systemModelId="8b738ea0-f89e-4627-8679-433616064e82"
/>
This isn't all that helpful - we also need to parse the activity names and geographies. We know the system model already, as we downloaded the apos release. We can get a dictionary mapping activity uuids with the following code:
from lxml import objectify
NS = "{http://www.EcoInvent.org/EcoSpold02}"
ACTIVITIES_FP = RELEASE_PATH / "MasterData" / "ActivityIndex.xml"
GEOGRAPHIES_FP = RELEASE_PATH / "MasterData" / "Geographies.xml"
ACTIVITY_NAME_FP = RELEASE_PATH / "MasterData" / "ActivityNames.xml"
SPECIAL_ACTIVITY_TYPE_MAP: dict[int, str] = {
0: "ordinary transforming activity (default)",
1: "market activity",
2: "IO activity",
3: "Residual activity",
4: "production mix",
5: "import activity",
6: "supply mix",
7: "export activity",
8: "re-export activity",
9: "correction activity",
10: "market group",
}
geographies_mapping = {
elem.get("id"): elem.name.text
for elem in objectify.parse(open(GEOGRAPHIES_FP))
.getroot()
.iterchildren(NS + "geography")
}
activity_names_mapping = {
elem.get("id"): elem.name.text
for elem in objectify.parse(open(ACTIVITY_NAME_FP))
.getroot()
.iterchildren(NS + "activityName")
}
activity_mapping = {
elem.get("id"): {
"name": activity_names_mapping[elem.get("activityNameId")],
"geography": geographies_mapping[elem.get("geographyId")],
"start": elem.get("startDate"),
"end": elem.get("endDate"),
"type": SPECIAL_ACTIVITY_TYPE_MAP[int(elem.get("specialActivityType"))],
}
for elem in objectify.parse(open(ACTIVITIES_FP))
.getroot()
.iterchildren(NS + "activityIndexEntry")
}
We now have something a little more usable:
activity_mapping["f7e93a25-56e4-4268-a603-3bfd57c79eff"]
{
'name': '2-butanol production by hydration of butene',
'geography': 'Global',
'start': '1981-01-01',
'end': '2005-12-31',
'type': 'ordinary transforming activity (default)'
}
Products: IntermediateExchanges.xml
Here is an example element from IntermediateExchanges.xml:
<intermediateExchange
id="42761d87-05d9-4877-b21e-001ecf0c747d"
unitId="487df68b-4994-4027-8fdc-a4dc298257b7"
>
<name xml:lang="en">trawler maintenance, steel</name>
<unitName xml:lang="en">kg</unitName>
<classification classificationId="e322cd45-aa14-4e64-946d-1a51874567d4">
<classificationSystem xml:lang="en">CPC</classificationSystem>
<classificationValue xml:lang="en">
8729: Maintenance and repair services of other goods n.e.c.
</classificationValue>
</classification>
<classification classificationId="39b0f0ab-1a2f-401b-9f4d-6e39400760a4">
<classificationSystem xml:lang="en">By-product classification</classificationSystem>
<classificationValue xml:lang="en">allocatable product</classificationValue>
</classification>
<comment xml:lang="en">Maintenance of a trawler, per 1000 kg of light ship weight (LSW) over 35 years
lifetime. Regressions based on mainly primary data were created to relate the weight of each
inventory item to a purse seiner's LSW, adjusted for trawler's gear. The list of inventory items
(granularity) contribute >95% of environmental impacts, as described in the reference
publication.</comment>
<productInformation>
<text xml:lang="en" index="1">Maintenance of a steel trawler, involving repairing work on the
hull and structural elements, gear repairing and/or partial replacement, engine maintenance,
replacement of smaller motors and pumps, repainting, etc.</text>
</productInformation>
</intermediateExchange>
This is nicer, as we don't need to load additional files:
PRODUCTS_FP = RELEASE_PATH / "MasterData" / "IntermediateExchanges.xml"
def maybe_missing(
element: objectify.ObjectifiedElement, attribute: str, pi: bool | None = False
):
try:
if pi:
return element.productInformation.find(NS + "text")
else:
return getattr(element, attribute).text
except AttributeError:
return ""
product_mapping = {
elem.get("id"): {
"name": elem.name.text,
"unit": elem.unitName.text,
"comment": maybe_missing(elem, "comment"),
"product_information": maybe_missing(elem, "productInformation", True),
"classifications": dict(
[
(c.classificationSystem.text, c.classificationValue.text)
for c in elem.iterchildren(NS + "classification")
]
),
}
for elem in objectify.parse(open(PRODUCTS_FP)).getroot().iterchildren()
}
Ecosphere flows: ElementaryExchanges.xml
Here is an example element from ElementaryExchanges.xml:
<elementaryExchange
id="38a622c6-f086-4763-a952-7c6b3b1c42ba"
unitId="487df68b-4994-4027-8fdc-a4dc298257b7"
formula="C4H10O2"
casNumber="000110-63-4"
>
<name xml:lang="en">1,4-Butanediol</name>
<unitName xml:lang="en">kg</unitName>
<compartment subcompartmentId="e8d7772c-55ca-4dd7-b605-fee5ae764578">
<compartment xml:lang="en">air</compartment>
<subcompartment xml:lang="en">urban air close to ground</subcompartment>
</compartment>
<synonym xml:lang="en">butane-1,4-diol</synonym>
<synonym xml:lang="en">Butylene glycol</synonym>
<property propertyId="6393c14b-db78-445d-a47b-c0cb866a1b25" amount="0"/>
<property propertyId="6d9e1462-80e3-4f10-b3f4-71febd6f1168" amount="0"/>
<property propertyId="a9358458-9724-4f03-b622-106eda248916" amount="0"/>
<property propertyId="c74c3729-e577-4081-b572-a283d2561a75" amount="0.533098393070742"/>
<property propertyId="3a0af1d6-04c3-41c6-a3da-92c4f61e0eaa" amount="1"/>
<property propertyId="67f102e2-9cb6-4d20-aa16-bf74d8a03326" amount="1"/>
</elementaryExchange>
Properties can be very useful, but we don't need them to build the matrix, so will skip them for now:
FLOWS_FP = RELEASE_PATH / "MasterData" / "ElementaryExchanges.xml"
ecosphere_flows_mapping = {
elem.get("id"): {
"name": elem.name.text,
"unit": elem.unitName.text,
"chemical_formula": elem.get("formula") or None,
"CAS": elem.get("casNumber") or None,
"compartments": [
elem.compartment.compartment.text,
elem.compartment.subcompartment.text,
],
"synonyms": [obj.text for obj in elem.iterchildren(NS + "synonym")],
}
for elem in objectify.parse(open(FLOWS_FP))
.getroot()
.iterchildren(NS + "elementaryExchange")
}
Ceci n'est pas un processus
Ecoinvent tries to model our world, and our world is messy and complicated. We already discussed how some processes can be multifunctional, and that we need to have each process be associated with one and only one reference product. The complication is that the processes we extracted from ActivityIndex.xml could still be multifunctional - in other words, the data in activity_mapping can be associated with more than one process node in our graph.
Let's find the process with the most instances:
product_list, process_list = [], []
for filepath in (RELEASE_PATH / "datasets").iterdir():
if ".spold" in filepath.name:
process, product = filepath.name.replace(".spold", "").split("_")
process_list.append(process)
product_list.append(product)
from collections import Counter
Counter(process_list).most_common(10)
[('9aac0778-3c9c-4ca6-b3dd-0be8226231e1', 20),
('2b856090-9c59-4de8-819c-eaf92a8575aa', 19),
('50116c55-67c9-489f-b2f9-ce04f0d62a8b', 17),
('3a06bdf5-24c4-43c6-8bfb-b8e4ec829916', 10),
('e92d2e87-3ff5-4bc8-9a46-affcc4e0b068', 10),
('562af63a-2c99-4896-ad9c-dfddaa86e36d', 9),
('f761c9ab-3ffc-479d-8f51-b4e33fd8d6a5', 9),
('8980bfa0-a957-4a1f-9a63-8c3a26a04cce', 9),
('35aad4e8-0882-4d98-8377-8c9bddd31d3f', 8),
('7e7169e9-ad99-443c-942f-b36e28868b45', 7)]
What process is it?
activity_mapping['9467f05a-e10c-4c11-9559-4c2b0838b5dc']
{
'name': 'primary zinc production from concentrate',
'geography': 'Rest-of-World',
'start': '2015-01-01',
'end': '2021-12-31',
'type': 'ordinary transforming activity (default)'
}
What are the reference products for zinc production?
zinc_products = []
for filepath in (RELEASE_PATH / "datasets").iterdir():
if ".spold" in filepath.name:
process, product = filepath.name.replace(".spold", "").split("_")
if process == '9aac0778-3c9c-4ca6-b3dd-0be8226231e1':
zinc_products.append(product_mapping[product]['name'])
sorted(zinc_products)
['ammonium sulfate',
'cadmium',
'cadmium sludge from zinc electrolysis',
'cobalt',
'copper concentrate, sulfide ore',
'copper sulfate',
'copper, cathode',
'gold',
'gypsum, mineral',
'heat, from steam, in chemical industry',
'indium rich leaching residues, from zinc production',
'iron scrap, unsorted',
'lead',
'lead concentrate',
'silver',
'sulfur',
'sulfur dioxide, liquid',
'sulfuric acid',
'zinc',
'zinc monosulfate']
It's even worse for products - the data in product_mapping is for generic products like this one:
product_mapping['66c93e71-f32b-4591-901c-55395db5c132']
{
'name': 'electricity, high voltage',
'unit': 'kWh',
'comment': '',
'product_information': ('This product represents electrical energy measured in kWh. If electricity '
'is taken from a market for electricity, the transmission infrastructure, '
'country-specific losses and transformation losses (for markets for medium '
'and low voltage) are included. Covers voltages above 24 kV. '),
'classifications': {
'By-product classification': 'allocatable product',
'CPC': '17100: Electrical energy'
}
}
As ecoinvent has electricity mixes for over one hundred countries, this product is the reference product for over one hundred processes, and therefore needs to be in our graph as over one hundred different nodes. But it's actually much more than that, as there are multiple generators producing high voltage electricity in each country:
Counter(product_list)['66c93e71-f32b-4591-901c-55395db5c132']
2172
Uniquely identifying process and product nodes
How then do we identify unique process and product nodes? Their UUIDs aren't enough, nor are their attributes like name, location, as these map one to one with their UUIDs. We have to take the combination of process and reference product UUIDs to have a guarantee of uniqueness. This is why the unit process datasets have the names that they do - it is a process UUID, and underscore, and then a product UUID.
We could just take the filename. It would be enough, but this approach has some drawbacks. The UUIDs are generated randomly, and will change from ecoinvent version to version, and even from system model to system model [3]. We could also use a UUID generator, but this would be different every time the script was run. Instead, we can use the combined attributes of the process and reference product to have an identifier which is useful across versions and reproducible.
Which attributes should we use? For a process, we know we need name and geography. In the future, ecoinvent could have different processes across time; however, this isn't available yet, and including timestamps will break compatibility across versions. We also don't need the activity type, as we don't have processes with the same name but with a different activity type.
For products, we have a name and a unit. The classifications and product information could change between versions but this isn't a change in the meaning of the node, just the level of detail provided per release, so we ignore this for now.
There is one more element we need - a way to distinguish between products and processes. Let's call this type, with the values product and process.
import hashlib
_ = lambda str: str.encode("utf-8")
def unique_identifier(process_dict: dict, product_dict: dict, type: str) -> str:
return hashlib.md5(
_(process_dict["name"])
+ _(product_dict["name"])
+ _(product_dict["unit"])
+ _(process_dict["geography"])
+ _(type)
).hexdigest()
What about ecosphere flows
Ecosphere flows are much easier - we can just use the ecosphere_flows_mapping! These ids are unique, and are shared as much as possible across system models and releases.
Parsing unit process datasets
What information do we need when we parse the unit process datasets? Each dataset will be one new process node and one new product node, and we need to keep track of them, together with their unique identifiers. We will also extract a lot of edges. Let's store edges as dataclasses:
from dataclasses import dataclass
@dataclass
class TechnosphereEdge:
source: str # Our unique identifier
target: str # Our unique identifier
amount: float
positive: bool = True
@dataclass
class EcosphereEdge:
flow: str # ecoinvent UUID
process: str # Our unique identifier
amount: float
In the technosphere - the interaction between processes and products - we need to know if the products are being consumed, in which case they would need a negative sign, or being produced, where they would be positive. The numbers in the unit process dataset won't reflect this bifurcation. As usual, the ecosphere is easier - we can just insert the amounts from the ecosphere edges.
There is one last wrinkle before we can parse 20.000 XML files. In the definition of edges, the producing process normally has its UUID given in the attribute activityLinkId (don't ask) - but not always! If this attribute isn't present, it is a production edge, and we can take the UUID of the unit process dataset itself.
We will use the pyecospold library as it has a few convenience functions. This library is quite strict, and you could get errors if invalid data is passed. One could always use bare lxml in that case.
import pyecospold
from pyecospold.model_v2 import IntermediateExchange, Activity, FlowData
from tqdm import tqdm
Let's define our data containers and some helper functions:
process_nodes, product_nodes = {}, {}
technosphere_edges, ecosphere_edges = [], []
INPUTS = ("Materials/Fuels", "Electricity/Heat", "Services", "From Technosphere (unspecified)")
def get_process_id(edge: IntermediateExchange, activity: Activity) -> str:
return edge.activityLinkId or activity.id
def reference_product(flows: FlowData) -> str:
candidates = [
edge for edge in flows.intermediateExchanges
if edge.groupStr == "ReferenceProduct"
and edge.amount != 0
]
if not len(candidates) == 1:
raise ValueError("Can't find reference product")
return candidates[0].intermediateExchangeId
Finally, we can iterate over all inventory datasets:
for filepath in tqdm((RELEASE_PATH / "datasets").iterdir()):
if not filepath.name.endswith(".spold"):
continue
ecospold = pyecospold.parse_file_v2(filepath)
activity = ecospold.activityDataset.activityDescription.activity[0]
this_process = activity_mapping[activity.id]
this_product = product_mapping[reference_product(ecospold.activityDataset.flowData)]
this_process_id = unique_identifier(this_process, this_product, "process")
this_product_id = unique_identifier(this_process, this_product, "product")
process_nodes[this_process_id] = (this_process, this_product)
product_nodes[this_product_id] = (this_process, this_product)
for edge in ecospold.activityDataset.flowData.intermediateExchanges:
if not edge.amount:
continue
other_process = activity_mapping[get_process_id(edge=edge, activity=activity)]
other_product = product_mapping[edge.intermediateExchangeId]
other_product_id = unique_identifier(other_process, other_product, "product")
is_input_edge = edge.groupStr in INPUTS
if is_input_edge:
technosphere_edges.append(TechnosphereEdge(
source=other_product_id,
target=this_process_id,
amount=edge.amount,
positive=False
))
else:
technosphere_edges.append(TechnosphereEdge(
source=this_process_id,
target=other_product_id,
amount=edge.amount,
positive=True
))
for edge in ecospold.activityDataset.flowData.elementaryExchanges:
ecosphere_edges.append(EcosphereEdge(
flow=edge.elementaryExchangeId,
process=this_process_id,
amount=edge.amount
))
What about LCIA
We need LCIA data - impact categories and characterization factors - to impact assessment calculations. This data is provided in a completely different format because... reasons?
We can load the excel workbook as pandas dataframes:
import pandas
characterization_factors = pandas.read_excel(
LCIA_PATH / "LCIA_implementation_3.7.1.xlsx", sheet_name="CFs"
)
characterization_units = pandas.read_excel(
LCIA_PATH / "LCIA_implementation_3.7.1.xlsx", sheet_name="units"
)
This is already a decent format, though we would need to link the ecosphere flow names and compartments to the UUIDs. But as we were using dataclasses for other edges, let's treat characterization in a similar way, and get references to the unique identifier while we are at it:
@dataclass
class CharacterizationFactor:
flow: str
amount: float
lcia_reverse_mapping = {
(v['name'],) + tuple(v["compartments"]): k
for k, v in ecosphere_flows_mapping.items()
}
impact_categories = {
tuple(obj[:3]): {
'cfs': []
}
for obj in characterization_factors.values.tolist()
}
for obj in characterization_factors.values.tolist():
impact_categories[tuple(obj[:3])]['cfs'].append(
CharacterizationFactor(
flow=lcia_reverse_mapping[tuple(obj[3:6])],
amount=obj[6]
)
)
for obj in characterization_factors.values.tolist():
impact_categories[tuple(obj[:3])]['unit'] = obj[3]
Version history
V2 (2023-11-06)
- Skip technosphere edges with amount 0
- Condense code to a single class in Notebook
V1 (2023-11-05)
Initial publication
Footnotes
| [1] | Brightway uses the term biosphere instead of ecosphere, but we want to be clear that the ecosphere includes both biotic and abiotic objects. |
| [2] | The amount can include uncertainty, though uncertainty isn't considered in this post as it makes the code longer and harder to understand. |
| [3] | It seems like some UUID are stable, but I don't really understand how stays the same and what changes. If I calculated correctly, around 100 of around 20 thousand files had the same filename in 3.7.1 and 3.8, which is more than zero, but still pretty small. |